
1. 什么是流式接口
流式接口(Streaming API)是一种实时数据传输机制,允许服务器在处理完成之前就开始向客户端发送数据。与传统的请求-响应模式不同,流式接口建立连接后会持续发送数据,直到完成整个响应或连接关闭。
常见的流式接口技术包括:
- Server-Sent Events (SSE)
- WebSockets
- HTTP Chunked Transfer Encoding
- gRPC Streaming
在AI大模型应用中,流式接口尤为重要,因为它能让用户在模型生成完整回答之前就开始看到部分响应,大大提升了用户体验。
2. 为什么需要对流式接口进行压测
2.1 流式接口的特殊性
流式接口与传统API有本质区别:
- 长连接:需要维持较长时间的TCP连接
- 实时性:数据需要低延迟传输
- 资源消耗:服务器需同时维护大量连接和数据流
2.2 关注首个Token的响应时间
在流式接口压测中,首个Token(或首个有效数据包)的响应时间是一个关键指标,原因如下:
- 用户体验直接相关:首个Token响应时间决定了用户从发送请求到看到第一个响应的等待时间,直接影响用户感知的系统响应速度。
- 系统处理能力指标:首个Token响应时间反映了系统在负载下的初始处理能力,包括请求接收、验证、模型加载和初始推理时间。
- 资源瓶颈识别:通过监测首个Token响应时间的变化,可以识别系统在不同负载下的瓶颈点。
- 区别于总响应时间:流式接口的总响应时间受内容生成长度影响较大,而首个Token响应时间更能反映系统本身的性能。
- 横向比较基准:作为标准化指标,便于在不同配置、不同版本间进行性能比较。
2.3 为什么需要使用代码实现流式接口压测
JMeter等传统压测工具的基础组件在处理流式接口时存在明显局限性:
- 无法捕获首个Token响应时间:JMeter的HTTP Sampler默认只记录完整响应的时间,无法识别和记录流式数据中首个有效数据包的到达时间。对于流式接口,这意味着它只能测量从请求发起到流结束的总时间,而非用户实际感知的首次响应时间。
- 缺乏流式数据解析能力:标准组件无法实时解析流式数据中的特定内容(如我们需要识别的code:3标记),因此无法基于内容触发计时结束。
- 连接处理机制不适配:JMeter的HTTP请求采样器针对的是短连接请求-响应模型,对于需要保持长时间连接的流式接口支持有限。
- 超时处理不灵活:流式接口可能需要长时间保持连接,而标准组件的超时处理机制难以满足这一需求。
- 无法自定义结束条件:流式接口的结束条件多样(如特定标记、空闲超时、最大行数等),而标准组件无法灵活设置这些条件。
通过使用JSR223 Sampler编写自定义代码,我们可以:
- 精确测量首个Token响应时间:通过代码识别首个有效数据包(如包含code:3的行),并在此时标记响应时间。
- 自定义数据解析逻辑:可以编写特定逻辑来解析和处理SSE格式的数据流。
- 灵活控制连接生命周期:可以根据业务需求精确控制连接的建立、维持和关闭。
- 实现多种结束条件:可以根据实际需求设置多种流结束条件,如特定标记、数据超时、最大行数等。
- 收集丰富的统计信息:除了响应时间外,还可以收集其他有价值的指标,如code:3出现次数、总行数等。
总之,虽然JMeter提供了强大的基础功能,但对于流式接口的特殊需求,使用代码实现自定义采样器是一种更加精确和灵活的解决方案。
3. JMeter针对GPTBots流式接口的压测方案
3.1 压测方案概述
本文档提供的压测方案基于Apache JMeter,使用JSR223 Sampler实现对流式接口的压测。主要特点:
- 使用Java代码直接发起HTTP请求
- 支持SSE (Server-Sent Events)格式的响应解析
- 专注于测量GPTBots流式接口首个有效响应包(code:3)的响应时间
- 提供详细的统计信息和调试数据
3.2 压测指标说明
在本方案中,我们主要关注以下GPTBots的接口指标:
- 首个code:3响应时间:从请求发出到接收到第一个包含code:3的响应的时间
- code:3出现次数:整个流式响应中code:3出现的总次数
- 总响应行数:接收到的总响应行数
- 流结束状态:流是否正常结束及结束原因
4. JSR223 Sampler脚本详解
以下是JSR223 Sampler中使用的Groovy脚本,用于实现流式接口压测:
import java.net.URL
import java.net.HttpURLConnection
import java.io.BufferedReader
import java.io.InputStreamReader
import java.io.OutputStreamWriter
// 目标流式接口URL
String sseUrl = 'https://www.gptbots.ai/v2/conversation/message'
// 创建一个新的请求体,包含必要字段
def postBody = """
{"conversation_id": "xxxxxxxxxxxxxxxx",
"response_mode": "streaming", // 指定使用流式响应模式
"messages": [
{
"role": "user",
"content": "你好啊"
},
{
"role": "assistant",
"content": "我是V2版本"
},
{
"role": "user",
"content": "写一篇关于母爱的作文"
}
],
"conversation_config": {
"long_term_memory": false,
"user_current_time": "October 16, 2024, 3:30 PM ,GMT+9",
"short_term_memory": false
}
}
"""
// 记录请求开始时间,用于计算响应时间
long startTime = System.currentTimeMillis()
// 初始化变量,用于存储响应数据和统计信息
StringBuilder responseBuilder = new StringBuilder() // 存储响应内容
int responseCode = 0 // HTTP响应状态码
String errorMessage = "" // 错误信息
boolean firstCode3Found = false // 是否找到第一个code:3
long firstCode3Time = 0 // 第一个code:3的时间戳
String firstCode3Line = "" // 第一个code:3所在行内容
int code3Count = 0 // code:3出现的总次数
int totalLineCount = 0 // 总响应行数
boolean streamEnded = false // 流是否结束
String endReason = "未结束"; // 流结束原因
try {
// 创建HTTP连接
HttpURLConnection connection = (HttpURLConnection) new
URL(sseUrl).openConnection()
connection.setRequestMethod('POST') // 设置POST方法
connection.setDoOutput(true) // 允许输出
connection.setRequestProperty('Content-Type', 'application/json') // 设置内容类型
connection.setRequestProperty('Accept', 'text/event-stream') // 接受SSE格式响应
connection.setConnectTimeout(10000) // 连接超时:10秒
connection.setReadTimeout(60000) // 读取超时:60秒
// 添加更多HTTP请求头
connection.setRequestProperty('User-Agent', 'JMeter/5.5')
connection.setRequestProperty('Accept-Encoding', 'gzip, deflate, br')
connection.setRequestProperty('Connection', 'keep-alive')
// 添加认证头
connection.setRequestProperty('Authorization', 'xxxxxxxxxxx')
// 写入POST请求体
OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream(), 'UTF-8')
writer.write(postBody)
writer.flush()
writer.close()
// 获取HTTP响应状态码
responseCode = connection.getResponseCode()
if (responseCode >= 200 && responseCode < 300) { // 成功响应(2xx)
// 读取响应流
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), 'UTF-8'))
String line
// 设置最大等待时间和无数据超时时间
long maxWaitTime = System.currentTimeMillis() + 180000; // 最多等待180秒
long noDataTimeout = 180000; // 180秒无数据则认为流结束
long lastDataTime = System.currentTimeMillis();
// 记录前30行响应,用于调试
int debugLineCount = 0
responseBuilder.append("First 30 response lines:\n")/
/ 用于检测连续空行的计数器
int emptyLineCount = 0;
// 持续读取响应流,直到达到最大等待时间
while (System.currentTimeMillis() < maxWaitTime) {
line = reader.readLine() // 读取一行响应
// 处理空行或null情况
if (line == null || line.trim().isEmpty()) {
// 增加空行计数
emptyLineCount++;
// 检查是否超过无数据超时时间
if (System.currentTimeMillis() - lastDataTime > noDataTimeout) {
endReason = "超过" + (noDataTimeout/1000) + "秒无数据";
streamEnded = true;
break;
}
// 等待100毫秒后继续读取
Thread.sleep(100);
continue;
}
// 重置空行计数和最后数据时间
emptyLineCount = 0;
lastDataTime = System.currentTimeMillis();
// 增加总行数计数
totalLineCount++;
// 记录前30行用于调试
if (debugLineCount < 30) {
responseBuilder.append(line).append("\n")
debugLineCount++
}
// 检查是否包含code:3(关键指标)
if (line.matches('.*"code"\\s*:\\s*3.*')) {
code3Count++ // 增加code:3计数
// 如果是第一次发现code:3
if (!firstCode3Found) {
firstCode3Time = System.currentTimeMillis() // 记录时间戳
firstCode3Line = line // 记录行内容
firstCode3Found = true // 标记已找到
// 当找到第一个code:3时,设置样本的结束时间为当前时间
SampleResult.sampleEnd()
}
}
// 检查是否是流的结束标志 - 使用code:0 + End关键字
if ((line.contains('"code": 0') || line.contains('"code":0')) &&
line.toLowerCase().contains("end")) {
endReason = "检测到结束标志(code:0 + End)";
streamEnded = true;
break;
}
// 如果已经接收了足够多的行,可以提前退出
if (totalLineCount > 200) {
endReason = "已接收超过200行";
streamEnded = true;
break;
}
}
// 如果达到最大等待时间还没结束,记录超时信息
if (System.currentTimeMillis() >= maxWaitTime) {
endReason = "达到最大等待时间(180秒)";
streamEnded = true;
}
// 关闭读取器
reader.close()
} else { // 错误响应(非2xx)
// 读取错误流
BufferedReader errorReader = new BufferedReader(new InputStreamReader(connection.getErrorStream(), 'UTF-8'))
String errorLine
StringBuilder errorResponse = new StringBuilder()
while ((errorLine = errorReader.readLine()) != null){
errorResponse.append(errorLine).append("\n")
}
errorReader.close()
errorMessage = errorResponse.toString()e
ndReason = "HTTP错误: " + responseCode;
}
// 关闭HTTP连接
connection.disconnect()
} catch (Exception e) {
// 捕获并记录异常
errorMessage = e.toString()
endReason = "异常: " + e.getMessage();
} finally {
// 如果没有找到code:3,在这里结束样本
if (!firstCode3Found) {
SampleResult.sampleEnd()
}
}
// 计算第一个code:3的响应时间
long responseTime = 0
if (firstCode3Found) {
responseTime = firstCode3Time - startTime // 计算响应时间
SampleResult.setSuccessful(true) // 设置测试成功
} else {
// 如果没有找到code:3,使用总请求时间作为响应时间
responseTime = System.currentTimeMillis() - startTime
SampleResult.setSuccessful(false) // 设置测试失败
}
// 设置JMeter聚合报告所需的信息
SampleResult.setResponseCode(firstCode3Found ? "200" : (responseCode > 0 ? Integer.toString(responseCode) : "500"))
SampleResult.setResponseMessage(firstCode3Found ? "Found code:3" : (errorMessage.isEmpty() ? "No code:3 found" : errorMessage))
// 添加统计信息到响应数据
responseBuilder.append("\n--- 统计信息 ---\n")
responseBuilder.append("HTTP Response Code: ").append(responseCode).append("\n")
responseBuilder.append("总行数: ").append(totalLineCount).append("\n")
responseBuilder.append("code:3 出现次数: ").append(code3Count).append("\n")
responseBuilder.append("流是否正常结束: ").append(streamEnded).append("\n")
responseBuilder.append("结束原因: ").append(endReason).append("\n")
// 添加首个code:3的信息
if (firstCode3Found) {
responseBuilder.append("First code:3 time(ms): ").append(responseTime).append("\n")
responseBuilder.append("First code:3 line: ").append(firstCode3Line).append("\n")
} else {
responseBuilder.append("No code:3 found in response\n")
}
// 添加错误信息(如果有)
if (!errorMessage.isEmpty()) {
responseBuilder.append("Error: ").append(errorMessage).append("\n")
}
// 设置完整的响应数据
SampleResult.setResponseData(responseBuilder.toString(), "UTF-8")
5. 脚本关键点解析
5.1 核心测量指标:首个code:3响应时间
脚本的核心目标是测量从请求发出到接收到第一个包含code:3的响应包的时间。这是通过以下代码实现的:
// 检查是否包含code:3
if (line.matches('.*"code"\\s*:\\s*3.*')) {
code3Count++
if (!firstCode3Found) {
firstCode3Time = System.currentTimeMillis()
firstCode3Line = line
firstCode3Found = true
// 当找到第一个code:3时,设置样本的结束时间
SampleResult.sampleEnd()
}
}
5.2 流结束条件
脚本设置了多种流结束条件,以确保测试能够正常结束:
- 检测到结束标志:响应中包含code:0且包含End关键字
- 数据超时:180秒内没有新数据
- 达到最大行数:已接收超过200行数据
- 达到最大等待时间:总等待时间超过180秒
5.3 错误处理机制
脚本包含完善的错误处理机制,可以捕获并记录:
- HTTP错误(非2xx响应)
- 连接异常
- 读取超时
- 其他运行时异常
5.4 统计信息收集
脚本收集并展示了丰富的统计信息:
- HTTP响应码
- 总响应行数
- code:3出现次数
- 流结束状态及原因
- 首个code:3的响应时间和内容
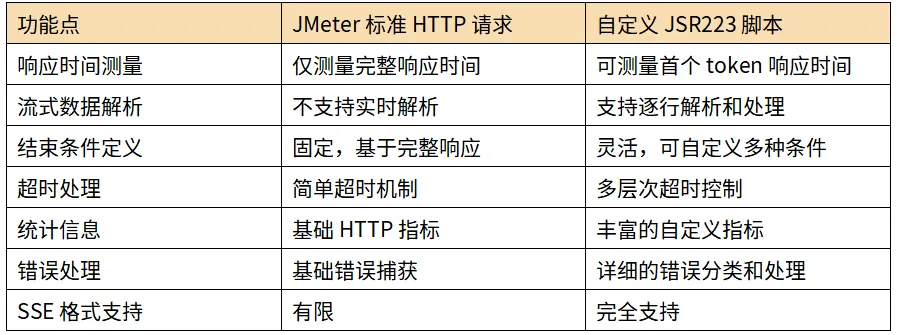
5.5 JMeter标准组件与自定义脚本的对比
下表对比了JMeter标准HTTP请求组件与我们的自定义JSR223脚本在处理流式接口时的关键差异:
6. JMeter配置步骤和实操
6.1 创建测试计划
6.2 添加线程组
6.3 配置JSR223 Sampler
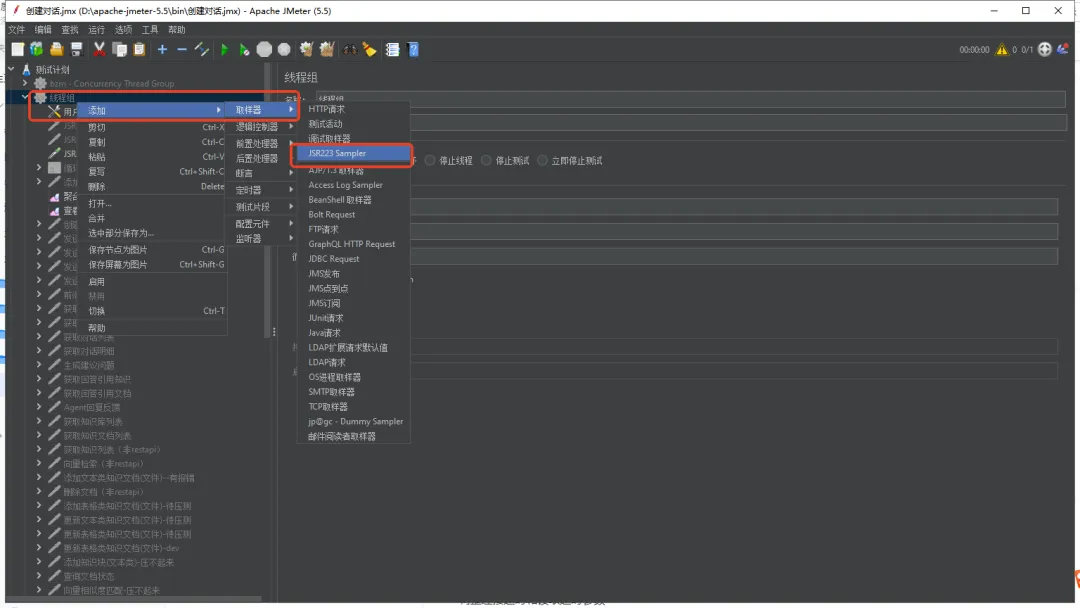
选择语言和添加代码
6.4 添加结果监听器
可输出文件
7. 结果分析与优化建议
7.1 如何解读测试结果
- 首个token响应时间:关注聚合报告中的响应时间,这反映了系统的初始响应速度
- 成功率:检查是否所有请求都成功接收到了code:3响应
- 吞吐量:每秒处理的请求数,反映系统整体处理能力
7.2 常见问题及解决方案
- 响应超时检查服务器资源使用情况调整连接超时和读取超时参数考虑增加服务器资源或优化服务端处理逻辑
- 未接收到code:3检查请求参数是否正确验证服务端是否正常工作查看详细错误日志
- 响应时间过长分析服务器CPU、内存使用情况检查网络延迟考虑优化模型加载和初始化过程
8. 高级配置选项
8.1 参数化测试
可以通过JMeter的CSV数据集配置或用户参数来参数化以下内容:
- 请求URL
- 会话ID
- 用户输入内容
- 认证令牌
8.2 分布式测试
对于大规模压测,可以配置JMeter的分布式测试模式,使用多台机器同时发起请求。
8.3 监控集成
建议将JMeter测试与服务器监控工具集成,同时监测:
- 服务器CPU、内存使用率
- 网络流量
- 数据库负载
- 模型推理性能
9. 总结
流式接口压测与传统API压测有显著不同,需要特别关注首个有效响应包的时间。由于JMeter等传统压测工具的标准组件无法满足流式接口的特殊需求,我们采用了JSR223 Sampler自定义脚本的方式,实现了对首个token响应时间的精确测量。
本文档提供的脚本专门针对流式接口特点设计,通过测量首个code:3响应时间,可以有效评估系统在负载下的性能表现。这种方法不仅克服了标准组件的局限性,还提供了更加丰富和精确的测试数据,为系统容量规划和性能优化提供了有力支持。
通过合理配置线程数、循环次数和思考时间,可以模拟不同规模的用户负载,全面评估流式接口的性能特性,为系统优化提供数据依据。







